 Image credit: Unsplash
Image credit: UnsplashAbstract
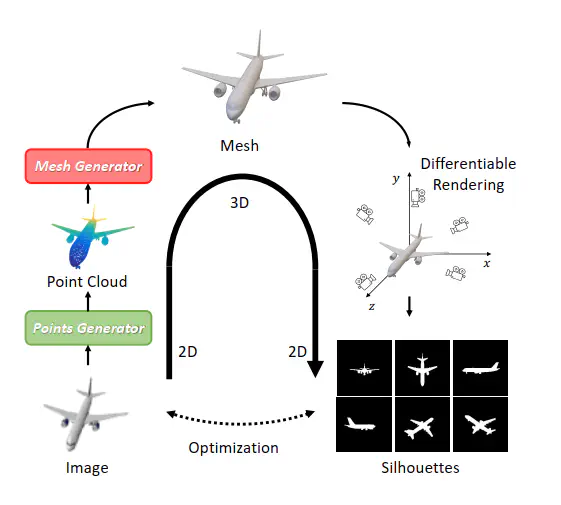
Single-view 3D object reconstruction is a fundamental and challenging computer vision task that aims at recovering 3D shapes from single-view RGB images. Most existing deep learning based reconstruction methods are trained and evaluated on the same categories, and they cannot work well when handling objects from novel categories that are not seen during training. Focusing on this issue, this paper tackles Zero-shot Single-view 3D Mesh Reconstruction, to study the model generalization on unseen categories and encourage models to reconstruct objects literally. Specifically, we propose an end-to-end twostage network, ZeroMesh, to break the category boundaries in reconstruction. Firstly, we factorize the complicated image-tomesh mapping into two simpler mappings, i.e., image-to-point mapping and point-to-mesh mapping, while the latter is mainly a geometric problem and less dependent on object categories. Secondly, we devise a local feature sampling strategy in 2D and 3D feature spaces to capture the local geometry shared across objects to enhance model generalization. Thirdly, apart from the traditional point-to-point supervision, we introduce a multi-view silhouette loss to supervise the surface generation process, which provides additional regularization and further relieves the overfitting problem. The experimental results show that our method significantly outperforms the existing works on the ShapeNet and Pix3D under different scenarios and various metrics, especially for novel objects.
Supplementary notes can be added here, including code, math, and images.
Xianghui Yang
Ph.D.
My research interests include Foundation Models, Large-Scale AI, Multimodal Learning, and 3D Vision.